关键词: 白盒測试 第4代 測试方法 4GWM 在线測试 持续測试 灰盒 脚本驱动 脚本桩
摘 要: 本文是第4代白盒測试方法的理论介绍,描写叙述3个关键领域内9项关键特征的概念与固有特征。同一时候介绍白盒測试发展历程,对照说明第4代白盒測试方法与以往測试方法的异同及优化要素。
缩略语:
4GWM:The 4th Generation White-box-testing Methodology,第4代白盒測试方法
XP:Extreme Programming,极限编程
TDD:Test Driven Development,測试驱动开发
IID:Incremental and Iterative Development,渐增迭代开发
CSE:Common Script Engine,通用脚本引擎(一种近似于python的脚本语言)
PCO:Points of Control and Observation,观察控制点
TDF:Test Design First,測试设计先行
MCDC:Modified Condition/Decision Coverage
背景
白盒測试的范围
白盒測试是软件測试体系中一个分支,測试关注对象是一行行可见代码,假设代码不可见就不是白盒,是黑盒測试了。白盒測试也通常被觉得是单元測试与集成測试的统称,但这个概念是相对的,与当前项目遵循的研发流程有关,某些流程把白盒測试划分为单元測试与集成測试,而另一些流程,把白盒測试划分为模块单元測试、模块系统測试、多模块集成測试,另一些流程把单元測试与集成測试混为一体,统称为持续集成測试。
随着測试技术的发展,白盒測试的概念也在发生变化,比方,本文提倡一种介于白盒与黑盒之间的灰盒操作模式,针对被測对象相同是可见源代码,这时,白盒測试不仅仅是白盒了。虽然假设此,我们仍遵循大家习惯的思维方式——把本文倡导的測试方法仍冠名为:第4代白盒測试方法(4GWM,The 4th Generation White-box-testing Methodology)。
本文讨论白盒測试方法,范围限定在功能測试之前,针对源代码行的全部測试,即,被測对象是看得到的功能源代码,每一个測试者必须先获得源代码才干实施測试。
第1代与第2代白盒測试
说到第4代白盒測试方法,就不能不回想前几代方法。在測试发展初期,測试工具非常不成熟,人们通常以单步调试取代測试,或採用assert断言、print语句等简单方式的组织測试体系,即我们所谓的第1代白盒測试,这一时期的測试是半手工的,没实现自己主动化,測试效果也严重依赖測试者(或者调试者)的个人能力,缺少统一规范的评判标准。
当然,调试算不算測试在业界尚存争议,单论调试的目的(为了定位问题)与操作方式(过程不可反复),不应把调试看作測试,但调试确能发现软件BUG,显然这也是一种測试手段。本文暂不评判调试用作測试手段是否合理,但有必要先确定调试是測试的某种形式,把它看作特定历史阶段或特定场景下的产物。特定历史阶段大家比較easy理解,调试伴随编程语言是天生的,測试工具却是后天形成,开发者总喜欢认调试器当亲妈,測试工具则是爱管无论的后妈。特定场景是什么?比方,某种生僻的RTOS平台根本找不到相应測试工具,怎么办?拿调试做測试是无奈之中的必定。这里,我们不否认调试也是一种測试,在此基础上再优化其操作过程,使调试能更好的服务于測试(下文介绍“灰盒调測”还有进一步论述)。
第1代白盒測试方法存在严重缺陷,主要有:測试过程难以重用,成功经验无法拷贝,測试结果也难以评估并用于改进,这些对于团队运作是很致命的。
到第2代白盒測试,上述主要缺陷得到克服,将測试操作改用一种形式化语言(通常称为測试脚本)来表述,脚本能够组合成用例,用例可组合成測试集,用例与測试集再统一到測试project中管理,把測试脚本保存到文件,重用问题攻克了。另外,代码覆盖率功能使測试结果能够评估,能直观的看到哪些代码或分支未被覆盖,然后有针对性的添加測试设计。眼下市面上有大量商用工具,如RTRT、CodeTest、Visual Tester、C++ Tester等都属于这第2代白盒測试工具。
第3代白盒測试方法
按理说,第2代白盒測试工具已经非常完好了,那第3代又是什么?
软件測试是一门复杂科学,支持自己主动測试与覆盖率评估后不见得就能成功实施白盒測试,尤其重要的是,第2代白盒測试攻克了反复測试问题,但没解决持续測试问题。简单来说,反复測试使測试操作能以规范格式记录,当被測对象没变化(或变化非常少)时,測试用例是可重用的,但假设源代码大幅调整(甚至重构),或者按迭代模式不停追加新功能时,怎样维持用例同步增长,并与源代码一起同步更新,已经不是简单的增强用例复用能力就能解决的。由于代码更新与用例更新交织进行,測试用例与被測源代码一样对等的成为日常工作对象,必定促使原有工作模式与測试方法产生变革,概括而言,白盒測试过程要从一次測试模式过渡到持续測试模式。
第3代白盒測试工具以xUnit为代表,包含JUnit、DUnit、CppUnit等,当然,我们列举xUnit工具,并不说这些第3代工具就比第2代工具要好。其实,眼下xUnit工具在功能上普遍赶不上第2代商用工具,很多xUnit工具甚至连主要的覆盖率都支持不了,况且,xUnit使用被測代码的编程语言写用例,普遍效率低下。这里,我们区别第2代方法与第3代方法,主要是測试理念上区别,而不以工具区别为基准,由于工具配套跟进还与诸多现实因素相关,是还有一层面话题。
第4代白盒測试方法的产生背景
xUnit是XP实践的重要支撑工具,XP作为一种软件开发方法论,整体尽管敏捷,但非常脆弱,它对程序猿非常友好,但对组织不是。以xUnit为代表的XP測试实践相同表现出这一特质,据已有案例分析,XP持续集成在java项目中成功的非常多,C++有一些, C语言项目就非常少了,为什么编程语言对持续集成的影响如此深远?
第4代白盒測试尝试解决软件測试的深层次矛盾:測试的投入产出比问题。大家知道,研发资源总是有限的,你能够把測试人员与开发者的比例配到1:1,也能够配到2:1,甚至5:1,但你做不到10:1、100:1,假设你有钱,也有人,全然能够按100:1或更高比例配置,这时全部測试瓶颈都没了,你能够让測试人员边喝咖啡边干活,由于每新写1行代码总有人编出100行脚本測试它,还怕产品不稳定吗?只是,疯子才会这么做,比尔盖兹有的是钱,一年捐款十多亿美金,但不见得微软旗下产品就常常让測试人员比开发者多出一倍。我的意思是,測试资源必定是受限的,这个前提下我们才讨论第1代、第2代白盒測试向第3代、第4代演化的必要性。基于相同原理的xUnit工具,针对不同开发语言效果截然不同,这说明什么?说明这样的实践的瓶颈仍在投入产出比上,也就是上面所说的1:1效果,还是2:1,抑或是5:1效果。
高效平台下的高效工具能够大幅提高測试效率,測试投入与开发投入之比小于1:1就能保证測试质量,项目就成功了,而低效平台下的低效工具,必定要投入很多其它測试资源(例如5:1)才干保证效果,拐点就在这儿,哪个公司禁得起5:1的測试投入?!从这个意上说,推出第4代白盒測试方法意义重大,我们要尝试解决决定项目成败的拐点问题。
事先申明一下,下文涉及持续集成与測试先行(或称測试驱动开发,TDD)实践,尽管这两者都是XP的重要组成部分,但我们无意宣扬XP,其实,真正能适应XP的项目范围并不宽,跳过需求与预设计直接启动项目的做法,足以让客户敬而生畏,把文档丢给狮子,那是无政府主义散兵游勇行径。只是,XP确有很多闪闪发光的实践,持续集成仅仅要运用恰当还是不错的模式,測试先行的理念也不赖,仅仅要只是度实施就好。
什么是第4代白盒測试方法
第4代白盒測试方法(4GWM)针对前几代測试方法不足提出,很多理念仍继承第2代与第3代測试方法。下表简要的列出第1代到第4代白盒方法的主要区别:
|
| 是否评估測试效果
| 是否自己主动測试
| 是否持续測试
| 是否调測一体
|
| 第1代白盒測试方法 | 否 | 否 | 否 | 否 |
| 第2代白盒測试方法 | 是 | 是 | 否 | 否 |
| 第3代白盒測试方法 | 是 | 是 | 是 | 否 |
| 第4代白盒測试方法 | 是 | 是 | 是 | 是 |
上表中,“是否评估測试效果”指是否有覆盖率或其他评估測试效果的指标,“是否自己主动測试”指是否形式化描写叙述測试操作并将它用于再次測试,“是否持续測试”指是否以按持续集成的模式开展測试,“是否调測一体”指是否将測试设计高效的融入产品编码与调试的日常实践之中。
第2代白盒測试与第3代的分水岭在于“是否持续集成”,也许您会说,我的项目也是常常出版本号,重复追加測试用例的呀,请注意,这是两个概念,Joel測试——改进代码的12个步骤中有一条:“编写新代码之前先修复故障吗?”,先修复故障是质量优先的项目,否则进度优先,这是两种全然不同的行事风格,前者时时測试,始终每写一两个函数就补全相关測试用例,測试实践是融入开发全过程的,而后者依时间表行事,測试仅是特定阶段里的任务。
对了,測试方法怎么跟软件开发方法扯上了?由于測试不是孤立的,測试是否有效强烈依赖于软件project方法,就像早期的开发语言,仅仅有assert语句与測试相关,发展到现有的C#,单元測试框架也是该语言的固有组件了。測试脚本也是一种产品代码,測试方法实际与软件开发方法密不可分的,这在第3代与第4代白盒測试中体现得非常充分。
第4代白盒測试方法相对第3代方法,添加了将測试过程(包含測试设计、运行与改进)高效的融入开发全过程,这里,“高效的”是关键词,那怎样才算高效呢?我们先简单了解4GWM在3个关键领域的9项关键特征,例如以下:
A. 第一关键域:在线測试
1、 在线測试驱动
2、 在线脚本桩
3、 在线測试用例设计、执行,及评估改进
B. 第二关键域:灰盒调測
4、 基于调用接口
5、 调试即測试
6、 集编码、调试、測试于一体
C. 第三关键域:持续測试
7、 測试设计先行
8、 持续保障信心
9、 重构測试设计
为什么持续集成
为什么要持续集成?这个问题太重要了,我们专门拎出来讲,请大家先不急于跳过本章去看4GWM的9个关键特征怎么定义的。
測试
Joel是个怪人,当然他不认识我,我拜读他的Blog才知道他的。这家伙总有很多稀奇古怪的思想在小脑瓜里蹦达,他是“常常放猫出来闲逛”的人。科学研究表明,人的大脑仅仅占体重2%,却消耗20%的能量,当大脑思考问题时,释放出的能量等同于夜间放一仅仅猫出来活动。他的“Joel说软件”专栏(www.joelonsoftware.com)非常火,有一些不乏真知灼见。比方,Joel測试——改进代码的12个步骤:
1、 有版本号控制机制吗?
2、 能一步完毕编译链接吗?
3、 每天都做编译吗?
4、 使用缺陷跟踪库吗?
5、 编写新代码之前先修复缺陷吗?
6、 有最新的进度表吗?
7、 有规格说明书吗?
8、 程序猿拥有安静的工作环境吗?
9、 你用到了你资金能力内可买到的最好工具吗?
10、 有測试人员吗?
11、 要求新聘人员在面试时编写代码吗?
12、 进行走廊可用性測试吗?
每一个问题能够回答“是”或者“否”,答“是”则加1分,得12分是完美,11分勉强接受,10分下面问题就大了,大家有兴趣看看你所在的组织能打多少分。
有測试人员吗?干嘛这么问,没測试人员还叫软件公司吗?这个问题并不可笑,还真有不少公司从未配置过专职測试人员。某白炽灯生产商在使用说明中特意声称,灯泡不能往嘴里塞,否则会出严重医学事故,说明书中还郑重其事的介绍灯泡不慎入口后,怎样求医,怎样抹润滑剂,怎样左转90度右转90度慢慢取出来。有人认为滑稽,谁白痴有事没事拿灯泡往嘴里送?即使放嘴里了也不用这么麻烦吧?非得试试,结果怎样?怎么也拿不出来了,仅仅得嘴里叼个灯泡打的上医院,最后,医生依照说明书费老劲才将那玩意卸下。所以,不要轻易否定前人经验,早有人试过了。
看看上面12个步骤,前5步活脱脱在讲怎样实施持续集成,若进一步了解其内容,大家最好还是浏览Joel的Blog原文。
持续集成不是XP专有实践
持续集成属于IID(持续迭代开发)方法学,在測试上,就现实而论是以xUnit实践为代表,持续集成概念被XP刻上深深烙印,但它确非XP专有实践。
早在20世纪60年代IBM的Federal Systems Division就開始应用IID开发模式了,源于IBM的集成产品开发流程(IPD)相对CMM,有个显著特征,它支持渐增迭代开发,尽管迭代频度比不上微软每日构造,但其理念仍是持续的迭代开发。有意思的是,IPD流程在华为公司本土化后,发展出“版本号火车”理论,有点相似于Scrum实践了,版本号火车不仅让产品(一般是大产品)版本号公布更加规范有序(由于火车总是定点出发的),也推动研发以更快频度推陈出新。
但眼下持续集成仍在有限范围能成功应用,微软无疑是个样板,毕竟纯软件产品easy实施每日构造,还有不少实践XP的项目,持续集成也运用得非常成功。所以,就总体而言,持续集成是否能成功,已经不是方法论问题,很多其它是IT工具怎样支撑的问题。
为什么持续集成
我们看一个实际案例,某通信产品在V1版本号编码完毕时,进行过规范的单元測试活动,之后V2、V3要不断添加功能、改动功能,就放弃单元測试了,当V3最后市场交付时统计发现,相对V1版本号,代码改动量已达到40%。QA从当中两个模块随机抽取100个问题单做缺陷分析,结果发现:第一个模块有50%的问题是在V1版本号单元測试结束后引入的,而还有一模块也有30%问题是单元測试后引入的。
也就是说,在第一次完整单元測试之后,代码改动了40%,也因此产生了40%的问题,因为增量白盒測试难以实施,这些问题都被遗留到后期功能測试中才发现。单元測试没能持续开展,带来后果是:发现问题不彻底,付出代价也更高。
上述模式在业界还普遍存在,我们称为一次測试,与持续測试不同,一次測试的測试设计仅仅做一次,用例仍可反复拿来跑,由于測试脚本与源代码不同步,用例维护是间歇进行的,或者干脆不维护。注意,一次測试与持续測试的区别不在于用例是否可重用,而在于測试设计的持续性。
很多企业做不到持续測试,其主要原因不是不想做,第一次測试都认真做了,追加代码或改动代码当然也要做測试,做不了是由于操作上存在困难。持续測试是须要一開始就规划,測试工具要配套跟进才干顺利实施的,对于老产品,代码修修补补,不管一次測试还是持续測试都非常难做得好。
引入持续測试,不仅以更低代价发现很多其它问题,更重的是,它体现了一个组织在測试理念上有质的飞跃。一次測试是一种被动測试,开发者受制于组织纪律(或主管、QA等压力)才去做,而持续測试是主动測试,大家在測试中尝到甜头,从原先不自觉状态,过渡到自发、自觉的时时做測试。这两种情形无疑有天差地别,前面提到的Joel測试12步骤,实际上是微软实践,与持续集成相关的有5条,足见它的重要性,是否引入持续集成,以及实施的效果怎样,实际反映了一流公司与二流公司的差距。
第4代白盒測试方法的关键特征
白盒測试是一项实践性非常强的技术,我们讲第4代白盒測试方法,离不开相关測试实践,尤其是測试工具支撑。本文的上篇先从理论上介绍什么是4GWM,下篇则结合详细測试工具介绍4GWM的典型实践。
在线測试
4GWM第一个关键域是在线測试,包含3个关键特征:
² 在线測试驱动
² 在线脚本桩
² 在线測试用例设计、执行,及评估改进
一次白盒測试中(即一个用例中)我们关注被測单元功能是否实现,被測单元作为总体,在特定环境下执行(比方某些全局变量取特定值、某些依赖线程或任务已启动等),具有特定的输入输出,这几项都属于“測试驱动”。另外,被測单元若能正确执行,还依赖它调用的子函数是否提供正常功能,这些子函数我们称为“測试桩”。分层结构例如以下图:

在三层实体中,被測单元是測试关注对象,要求尽可能真实,我们设法维持其原状,測试驱动与測试桩能够模拟(或叫仿真),同意存在一定失真,但要求尽可能高效,否则測试产出的拐点问题解决不了。
脚本驱动与脚本桩
先回答一个基础问题,编写測试用例应优先採用脚本语言,而不与被測代码使用同一的语言,为什么?
还是应为软件測试的深层次问题——投入产出比,假设被測编程语言的抽象度较低、封装性差,用起来就非常麻烦。比方拿C或C++写測试用例,得处处小心内存操作,要正常申请释放、注意不越界,时常关心使用变量是否安全、是否已初始化等。或许有人说,不正确, CppUnit中拿C++測C++,我用得非常爽呀?噢,没错,我得先恭喜这位老兄,安于现状不失为一种好品质。
我们设想一下,编写一万行C++代码,你要写多行代码測试它,一千行?两千行?不正确,是一万行,按业界普遍规律,測试代码行至少要与被測代码行数相当才见效果,測试代码要不要调试?当然要调,天哪,算出来的了,測试投入至少是开发投入的三、四倍才做得下来(后期还有功能測试、性能測试、兼容性測试等等,还要占用大量精力),这种项目是不是处在是否能成功的拐点上?所以,假设您还在用C、C++等过程语言写用例,请尽快换到脚本语言,如python、ruby、CSE等,用脚本语言能让你编写用例的效率提高3到5倍。
用脚本编写用例,意味着測试驱动与測试桩仿真也用脚本语言。我们看一下VcTester工具使用的測试脚本,假定被測对象是C代码的冒泡排序算法:
void BubbleSort(OBJ_DATA_PTR *ObjList, int iMax){ int i,j,exchanged; OBJ_DATA *tmp; for (i = 0; i < iMax; i++) // maximum loop iMax times { exchanged = 0; for (j = iMax-1; j >= i; j--) { if ( ObjCompare(ObjList[j+1],ObjList[j]) < 0 ) { // exchange the record tmp = ObjList[j+1]; ObjList[j+1] = ObjList[j]; ObjList[j] = tmp; exchanged = 1; } } if ( !exchanged ) return; }}
排序函数(BubbleSort)中调用了对象比較函数(ObjCompare),假定当前測试对象是BubbleSort函数,我们编写測试用比例如以下:
func StubFunc(vc): if vc.arg0->Data() < vc.arg1->Data(): return -1; end else return 1; end;vd.ObjCompare.stub(StubFunc); # 打脚本桩vd.BubbleSort(vd.gList,6); # 发起測试assert(vd.gList[0]->Data <= vd.gList[1]->Data); # 检查測试结果vd.ObjCompare.stub(nil); # 清除脚本桩
脚本驱动是指将被測系统的全局变量与全局函数映射到脚本系统,然后使用脚本读写C语言变量,调用C语言函数。在VcTester中,C语句的全局变量与函数映射到脚本的vd集合下,如上面脚本使用“vd.gList”读取C变量,使用“vd.BubbleSort()”调用C函数。
脚本桩是指定义一个脚本函数,然后让这个脚本函数取代某个C函数,打脚本桩是为了让一段脚本化測试逻辑,在动态运行中,取代被測系统中的桩函数。由于測试中我们常常要让某些子函数返回特定值,使被測函数的特定路径能被覆盖。上面样例定义了一个脚本桩函数StubFunc,拿这个脚本函数模拟对象比較功能,通过打桩替换C函数ObjCompare。
在线測试逻辑更新
4GWM引入脚本驱动与脚本桩,不仅仅是提高測试设计效率,还以此保障在线測试。所谓在线測试,是指被測程序启动后,用例在线设计、调试、执行,执行结果在线查看的測试方法。由于全部測试操作都在线进行,測试用例不必编译链接,被測程序也不用复位重起,被測环境(被測系统的变量、函数等属性)在线可查看,所以该測试模式非常高效,另外,各測试步骤所见即所得,人性化的操作过程非常easy被广大开发者接受。
脚本语言具有在线更新功能,比方定义一个脚本函数,调用一次后,发现某个地方处理不正确,于是重写这个函数,然后在线的更新这个函数定义。编译语言做不到这一点,改动代码后必须又一次编译链接,程序要复位重起,脚本语言省去了这些繁琐过程。比方,在GUI界面编写測试用例,定义測试桩函数,然后选择待运行的脚本区块,按一个快捷键,指定范围的脚本就运行,相关脚本函数定义马上被更新,脚本运行后的測试结果也马上打印输出。
拉通測试小循环
測试用例设计、调试、运行,及评估改进是一个闭环迭代,例如以下图:
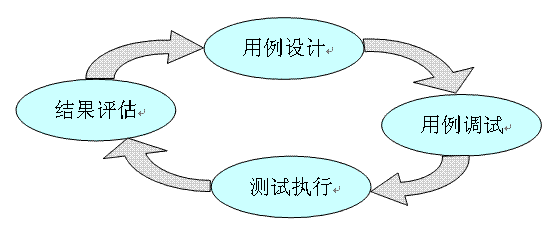
測试结果评估主要是覆盖率指标,包含:语句覆盖、分支覆盖、组合条件覆盖等,结果评估也是在线进行的,用例运行后,随即在线查阅覆盖率情况,针对未覆盖部分再添加用例。
当上图4个步骤都能在线操作后,測试小循环就拉通了,4GWM的第一个关键域(在线測试)的目的就在这儿,拉通測试小循环,是大幅度提高測试工作效率的第一环节。接下来通过灰盒调測,拉通开发大循环是提高效率的第二环节。
灰盒调測
4GWM第二个关键域是灰盒调測,包含3个关键特征:
² 基于调用接口
² 调试即測试
² 集编码、调试、測试于一体
白盒測试的粒度
白盒測试关注被測函数的功能表现,要关注到什么程度,在不同的測试实践与測试工具中要求各不同。我们能够简单的分为3个级别,一是源代码行级别,二是函数调用级别,三是组件接口级别。
源代码行级别具有调试特征,能够关注到函数内局部变量,当測试停留于该级别会显得过于细碎,由于结构化程序开发总是以函数为单位逐级划分功能的,函数内的代码稳定性差,变量定义常常变化,过程处理也常常调整。组件接口级别的測试对象仅关注到组件接口,如Corba接口、控件调用接口、消息队列接口等,这一级别的白盒測试无疑偏于粗放。
4GWM规定的白盒測试关注粒度是函数调用接口,即,測试设计仅仅关心函数的输入、输出,及该函数执行中对全局变量的影响,遵循例如以下原型:
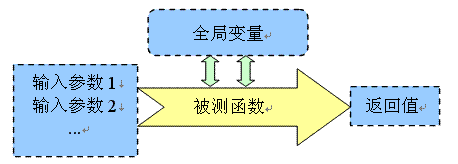
设计測试用例,先通过脚本构造被測函数的输入參数,改动特定全局变量,使被測函数处于某特定执行环境下,这两步属于測试驱动。然后调用被函数,最后推断測试结果,由于执行被測函数可能影响输入參数、全局变量与返回值,所以推断用例是否执行通过,观察对象也是这三者。在用例设计过程中,我们并不关心函数内局部变量怎样声明,也不关心函数内逻辑过程怎样处理,仅仅关心被測对象的输入与输出,这是一种典型的黑盒思维模式。
准确来说,4GWM是一种灰盒測试方法,虽然操作方式是黑盒的,但測试设计是白盒的,由于看得见源代码,測试设计能够有针对性的进行,測试过程评估也是白盒的,执行一遍用例后,查看哪些代码行有没跑到,再有针对性补充用例。所以,我们从总体来看,4GWM是介于黑盒与白盒之间的灰盒測试。
依据已有实践判断,上述灰盒模式关注的測试粒度是恰如其分的,既避开了调试操作的任意性,也使測试用例建立在较稳健的基础之上,仅仅要函数调用接口没变,局部变量改了或逻辑过程调整了,就不会影响已实用例。同一时候,黑盒操作方式附带白盒分析模式,保障了4GWM具有高效、便捷的特性。
检视器
检视器(Inspector)是4GWM推荐的測试辅助工具,它介于測试器(Tester)与调试器(Debugger)之间,是一种可以提供脚本化控制的粗粒度的调试器。使用检视器有助于把无规则的调试过程转化为规范的測试过程。
检视器有两种执行模式:断点调试模式与測试模式。前者在断点条件满足时进入单步跟踪状态,后者在断点上附加特定脚本语句(比方改动变量、检查变量值等),当断点条件满足附加语句即自己主动执行,此时断点仅作为一个观察控制点(Points of Control and Observation,PCO)存在,不用作交互调试目的。
一次典型的检视步骤例如以下图所看到的:
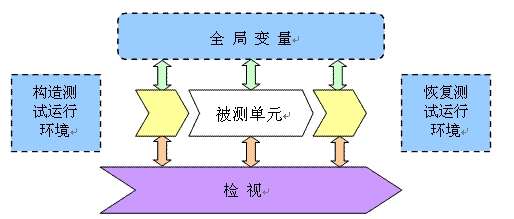
首先在被測函数上设置断点,接着用脚本构造调试环境,包含改动变量、设置脚本桩等,然后发起測试,在断点触发后的单步跟踪状态,观察各个变量值是否预期,还能够改动变量使被測函数中特定分支能够运行。最后在调试完毕时,能够将当前调试操作,包含设置断点、检查变量值是否预期、改动变量等,自己主动转化为測试脚本。
上述检视操作向自己主动脚本转换还解决測试数据构造问题,尤其在复杂系统中,构造測试数据比較麻烦,比方通信协议的消息包数据,创建消息后要填写数十,甚至数百个字段的值。 检视操作能够在函数调用链中插入一段脚本代码,比方被測代码先调用一个初始化协议消息的函数,得到正确消息包后传递给被測函数,我们通过插入脚本,在被測函数执行之前改动传入消息包的特定字段,从而实现特定路径的覆盖測试。採用该方法设计用例是很便宜的,直接重用被測系统的局部功能,免去了繁重的測试驱动构造工作。
检视过程相似于调试,主要区别例如以下:
1. 检视器断点仅仅在函数入口设置,调试器能够在随意语句设断点。
2. 检视既能够在IDE界面手工操作,也能够通过写脚本控制,调试器一般仅仅支持手工操作。
3. 检视器在断点状态下能够执行随意合法的測试脚本,调试器无此功能。
因为检视器与编程语言自带的调试器实现原理不同,普通情况下两者能够同一时候使用,可同一时候设置检视断点与调试断点。
调试就是測试
调试为了定位问题,測试是为了发现问题,两者虽不能互相替换,但当測试手段趋于丰富,測试工具也能越来多的承担调试职责。让測试工具承担部分调试功能,可在例如以下方面获益:
1. 调试与測试共享执行环境
被測代码片断是在特定环境下执行的,不管调试还是測试,都得先构造执行环境,比方准备特定的数据、改动状态变量、启动特定线程或任务。借助測试工具在线构造測试驱动与測试桩,调试环境能便利的搭建起来,并且,构造执行环境的脚本能直接在相关測试用例中重用。
2. 将不可反复的调试转化为可反复的測试
调试过程具有任意性与不可反复性,在哪儿设断点、怎样看变量、怎样单步跟踪都因人而异。调试的操作过程难被重用,不像測试用例,以形式化脚本记录操作过程,想怎么反复就怎么反复,上节介绍的检视器就是一种可反复的调试器。
操作自己主动反复是提高工作效率的基本途径,不必强求全过程反复,片断可反复就能大幅提高效率了。
3. 測试设计能够非常好的重用被測系统中局部功能
如上一节举例,直接调用被測系统的消息构造函数,能避开繁重的协议消息仿真工作。
4. 解决脚本调试与源代码调试的交叉影响问题
实践证明,白盒測试的大部分时间消耗在脚本编写与调试中,调试好的用例,运行差点儿不要时间(即使要时间,挪到晚上让它自己自己主动跑好了)。測试脚本调试与源代码调试是交叉进行的,单元測试中的源代码与測试脚本都不稳定,通常我们让脚本发起測试,须同一时候跟踪脚本与源代码,查看运行结果正不对。假设这两者调试过程是分离的,调源代码时不能看脚本,或调脚本时不能看被測变量,其操作过程必定很痛苦。
当測试承担起调试职责,两者合二为一,交叉影响的问题即自己主动解决。实事上,大家把測试当測试、调试当调试,非常大程度上是由于没把測试脚本也看作产品代码,不把它当成产品固有部件,假设观念转变过来了,測试脚本也是代码,调试脚本就是调试代码,两者本应合二为一的。当然,还存在工具的问题,缺少好工具,将两者强扭一起终于仍会不欢而散。
4GWM尝试让測试工具承担起90%的调试工作,全然替换并不是必要。假设測试工具能承担大部分调试,开发大循环就能拉通了。下图是开发与測试尚未拉通,是孤立两个过程的情况:
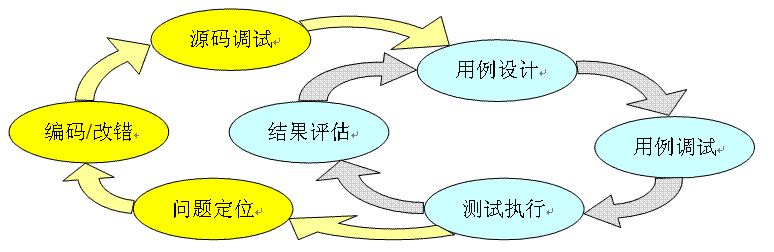
拉通开发大循环后,測试不再是独立的闭环过程,例如以下图:
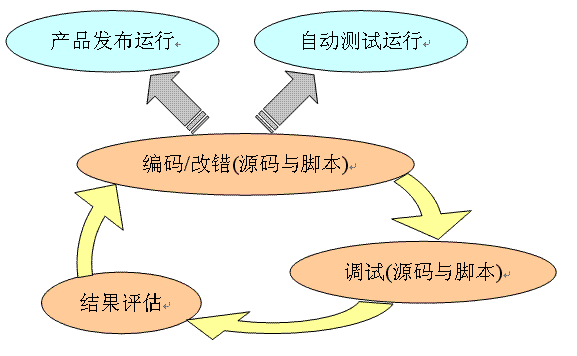
測试设计(即写脚本)与产品设计(即编码)融为一体,调试脚本与源代码成为开发者主要日常工作。上图的结果评估,对于測试脚本是覆盖率,对于产品源代码是其执行表现(其结果可能预期,也可能出差错了),评估这两者,再补充用例及完好源代码,之后进入下一轮迭代循环。
调试通过的脚本打包到測试project,就是可以支持每日构建的用例库;測试通过的源代码经release公布,就是在市场上能提供预期功能的正式产品。
编码、调试、測试集成平台
4GWM在方法论上要求大家把測试脚本也看成产品代码,以黑盒调測取代大部分单步调试,但方法论是否能顺利被实践支持,还严重依赖于測试工具的品质。为此,4GWM要限定測试工具必须将编码、调试、測试集成到一个平台。
该要求实际限定測试脚本要拥有与源代码一样的权益,因为历史原因,各主流语言的集成开发环境总是让代码能在同一平台下编辑、调试的,如今既然把脚本也看成一种代码,就应该赋予它同等权益。拿通俗的话来讲,我们要构造一种集成平台,集编码、调试、測试于一身,是为了让“測试”这个后妈晋升级为亲妈,原先“调试”是亲妈,占尽天时地利,最好还是从IDE让出一些位置。
把调測一体化平台作为4GWM特征之中的一个明白下来,能够防止4GWM在不同编程语言及不同測试工具下实施走样。请注意,集成平台的规定不是4GWM本质方法论,但4GWM对工具化支持有比較高要求,配套工具要有足够的功能,能让广大开发者随心所欲的使用測试手段替代调试。
持续測试
4GWM第三个关键域是持续測试,包含3个关键特征:
² 測试设计先行
² 持续保障信心
² 重构測试设计
測试设计先行
測试先行是XP典型实践,XP中的測试先行是Test Driven Development(TDD),4GWM规定的測试先行是Test Design First(TDF),两者主体内容应该一致,细节要求稍有差异。
为方便大家理解,我们还是从XP的TDD基础上介绍4GWM的TDF。TDD是測试驱动开发,測试代码在产品代码之前编写,要求产品先能測试,然后在解决这个问题过程中补充设计或完好设计。一个简单的TDD样例,比方我们要编写一个函数GetHash计算某对象的hash值,定义GetHash函数的原型后,即開始设计用例,如:
// 确定函数原型
int GetHash(void *obj)
{
assert(0,”Not define yet.”);
}
// 设计用例
assert( GetHash(newObject(12)) == 12 );assert( GetHash(newObject(”AName”)) == 63632 );
上述測试肯定通只是,所以要解决这个问题,先是整形对象的hash值算不正确,我们在GetHash函数中加入处理分支:
int GetHash(void *obj)
{
if ( ObjType(obj) == dtInt ) {
...
return iHash;
}
assert(0,”Not define yet.”);
}
然后,再次执行用例发现字串对象的hash值也不正确,再加入对应处理代码。
TDF也按上述模式操作,但相比TDD稍有差异,主要表如今:
1. TDD强调測试驱动开发,即:測试先做,然后在測试主导下完好被測系统。而TDF仅仅是要求測试设计先做,并不强制測试代码总比被測功能先跑起来。
TDD要求一開始就写规范的用例,而TDF很多其它的是让调试环境先跑起来,调測代码既能够是规范的用例,也能够是待整理的脚本,即草稿状态的用例。
2. TDD更倾向于自顶向下的开发模式,TDF则较少受此限制,实际操作时,使用最多的是混合模式。即:假设自顶向下比較easy操作,就自顶向下先设计用例,假设自顶向下不好操作,先自底向上先写底层代码也无妨。
TDF通常採用三文治操作模式,即:先设计少量用例,让调測环境顺利跑起来,接着补充功能代码,最后再添加用例使新写的代码能完整測试。由于功能编码夹在中间,成为三文治的馅,过程的两端都是用例设计。由于结构化设计的缘故,TDF三文治模式也是层层嵌套、依次深入的,先写高层次測试脚本,接着高层次编码,然后补充高层次測试设计,之后进入下一层结构化设计,相同先设计下层測试脚本,接着下层功能编码,再补充下层測试设计。
3. TDF要求尽可能高效的编写用例,调试操作能够转化成用例,已測试通过的功能也能够在用例中重用,TDD对此没有特别要求。
TDD与TDF都强调尽可能在编码之前设计用例,看得到代码后编写用例easy坠入惯性思维陷阱,比方,某个被測函数少了一个分支处理,看自己写的代码做測试,也相同easy忽略这个分支。所以,先写脚本后写代码能够检验设计是否合理,这时測试设计根据的是规格。
測试先行经XP实践论证,总体是可行的, Boby George与Laurie Williams的统计数据表明(參见《An Initial Investigation of Test Driven Development in Industry》),实施TDD,有87.5%的开发人员觉得能更好理解需求,有95.8%觉得TDD有助于降低bug,78%的人觉得TDD提高了生产率,另外还有92%的人觉得TDD能促进代码质量,79%的人觉得TDD有助于简化设计。同一时候,这份统计还表明,有40%开发人员表示採用TDD比較困难,困难主要原因在于看不到代码情况下先做測试设计,easy让人无所适从。
TDF在一定程度上克服TDD应用困难的弊端,它并只是于强调測试设计一定先于编码,但要求先行编写的測试脚本与代码能尽早展现功能,或尽早的验证规格,脚本与代码一起对等的被设计者用来实施他的意图——当然,遵循结构化设计原则,越高层越抽象的逻辑应先验证,越重要的功能也应先验证。尽早展现功能,也意味着:写一点測一点、測一点写一点,一有可展现或可调试的小功能,測试设计总与功能编码同步跟进的。
怎样持续保障信心
4GWM很强调维持良好的客户体验,在线測试保证白盒測试所见即所得,人性化操作催生快感,拉通測试小循环与开发大循环,使工作效率大幅提高,强化了这样的快感,如今再加一条:測试过程可度量,让开发人员至始至终都对自己的代码充满信心,巩固快感使个体愉悦延伸到团队愉悦。
白盒測试最重要的度量指标是覆盖率,包含语句覆盖、分支覆盖、条件覆盖、组合条件覆盖、路径覆盖、数据流覆盖等。设计測试度量标准,不是种类越多就越好,也是越高标准(如路径覆盖、MCDC覆盖)就越好,最重要的是,要恰如其分,另外还得考虑现实因素:測试工具能不能支持。尤其在持续測试模式下,恰当的选择覆盖指标尤显重要,要求过高使測试成为累赘,必定让持续測试做不下去。与一次測试不同,不恰当覆盖指标带来的负面影响,在持续迭代中放大了,稍过复杂就带来非常大伤害。
实践经验表明,常规的白盒測试拿语句覆盖与分支覆盖度量已经足够,对于局部逻辑复杂的代码,再增设MCDC覆盖就够用了。4GWM推荐把调用覆盖(近似于语句覆盖)当作主要測试指标,调用覆盖是观察函数调用与被调用关系的一种覆盖指标,由于4GWM以函数为单位关注測试过程,函数是识别不同測试及同一測试中不同分层的根据,以调用关系度量測试程度,是这样的基于调用接口、灰盒模式的測试方法论自然延伸。
除了覆盖率指标,我们还得差别经意測试与不经意測试。例如測试某特定分支设计一个用例,除了你期望的分支跑到外,同一函数中其他部分的某些分支也能跑到,这是不经意产生的覆盖率贡献。不经意測试使结果评估产生偏差,也给想偷懒的员工带来便利,例如,測试某通信产品,设计用例打一个电话,就可能贡献20%的覆盖率。
为避免上述情况,4GWM设计出还有一指标:測试设计程度(或称用例覆盖度),该指标分析測试project中,被測函数调用次数与该函数分支总数的关系。一个函数分支越多,就应设计很多其它的用例来測试它。用例覆盖度是作为基础条件參与測试评估体系的,设置门槛阀值,过了门槛条件,即使多设计用例也不给測试效果加分,但没过门槛,结果评估则是一票否决的。
4GWM要求測试工具以直观、简洁的方式随时统计測试程度。由于是增量式设计,被測代码与測试脚本都按对等速度递增的,測试评估先要求定义測试观察范围,选中当前关注的被測源文件与脚本文件,成为測试project,然后,工具始终以project为单位进行评估,在主操作界面显示一个标志灯,亮红灯表示当前測试未通过,有bug等待先解决,亮黄灯表示測试通过了但覆盖率指标不符合要求,亮绿灯表示满足覆盖指标而且測试通过。
遵循4GWM的软件开发过程,就是时时刻刻要让界面绿灯亮起的持续开发过程,这好比开车,功能编码是踩油门,測试编码是踩刹车,界面红绿灯是执法标准,仅仅亮绿灯才干往前走。规则已经非常清晰了,时时刻刻遵守交规就是持续信心的保障。
重构測试设计
做好人不难,难就难在一辈子都做好人(做坏人更难?没见过一辈子仅仅做坏事的人)。我们照章开车,没人给你开罚单,但不意味着项目就没问题了,方向走反了是南辕北辙,方向偏了可别指望歪打正着。相同,要让白盒測试能持续的跟进,非常重要一点,測试设计要能高速重构。软件设计总是难免出错,其实,多数产品开发都会经历几次局部重构,当被測代码大幅调整,规模与之对等的測试代码怎样高速修正成了迫切待解决的难题。
重构測试设计要根据被測代码,測试工具应保存近期绿灯状态时的源代码信息,比方,系统中都有哪些全局符号(变量、函数),符号是什么类型,被測函数都调用哪些子函数、都使用哪些全局变量等。重构測试设计时,根据历史被測代码与重构后代码的差异,自己主动分析当前哪些用例会受影响,怎样影响,再详细指出哪些脚本行应作调整。这好比开车走错路,要回头想想在哪个十字路口開始错的,错在哪个方向。当上述过程有工具帮我们分析,维护用例的效率就高多了。
结论
眼下,4GWM已有实践主要集中在C语言測试,在线測试、持续測试诸多实践非常早就有測试工具支持,已有数年应用积累。本文归纳的4GWM九大特征,都来源于白盒測试长期实践,先实践后总结,先有详细应用,然后归纳出通用方法。
这里再总结一下,上文介绍的3个关键域中,在线測试是基础,是维持良好客户体验的第一步,在线測试不仅拉通測试小循环,初步解放生产力,并且,在线特性让灰盒调測成为可能。灰盒调測拉通开发大循环,再次大幅度解放生产力。当測试效率两度提升后,持续集成就不再困难了。
參考资料
1. E. Michael Maximilien, "Assessing Test-Driven Development at IBM"
2. Joel Spolsky, "Joel On Software"
3. Elfriede, D. "Effective Software Testing:
50 Specific Ways to Improve your Testing"4. George, B. and Williams, L., "An Initial Investigation of Test-Driven Development in Industry"
5. Wayne Chan, "VcTester User Manual"
6. Philip M. Johnson, and Joy M. Agustin, "Keeping the coverage green: Investigating the cost and quality of testing in agile development"
7. IPL Information Processing Ltd, "Why Bother to Unit Test?"
================= END =============================
本专题相关的文章: